MySQL

- 세계에서 가장 많이 쓰이는 오픈 소스의 관계형 데이터베이스 관리 시스템
- 다양한 운영체제에서 사용할 수 있으며, 여러 가지의 프로그래밍 언어를 지원
- 크기가 큰 데이터 집합도 빠르고 효과적으로 처리할 수 있음
- 널리 알려진 표준 SQL 형식을 사용
- MySQL 응용 프로그램을 사용자의 용도에 맞게 수정할 수 있음
- 키워드와 구문에서 대소문자를 구분하지 않음
- DB 서버마다 독립적인 스토리지를 할당하는 방식을 사용
MySQL 장점
- 용량 & 처리 : 적은 용량 차지(1MB RAM), 매우 적은 오버 헤드, 빠른 처리 속도로 대용량 데이터 처리에 용이
- 접근성 : 다른 데이터 관리 툴에 비해 구조가 간단하여 사용이 쉬움
- 지원 : 다양한 프로그래밍 언어와 통합 가능, 거의 모든 운영체제에서 사용을 지원
- 유연성 : 유연하고 확장이 가능한 구조
- 가격 (오픈소스 - 무료 / 상업용 - 유료)
MySQL 단점
- 복잡한 쿼리 시 성능 저하
- 트랜잭션 지원이 완벽하지 않음
- 사용자정의 함수(UDF)의 사용이 쉽지 않고 유연하지 않음
MySQL 사용이 적합한 경우
- 분산 작업이 필요한 경우
: MySQL의 복제 기능 지원은 Primary-Secondary
또는 Primary-Primary 구조와 같은 분산 데이터베이스 설정에 적합함
- 웹 사이트 및 웹 애플리케이션
- MySQL은 인터넷을 통해 많은 웹 사이트와 애플리케이션을 지원함
- 설치가 쉽고, 속도가 빠르면며, 확장성이 좋음
- 향후 성장이 예상되는 제품
: MySQL의 복제 기능 지원은 수평적 확장에 도움이 될 수 있음
💡 MySQL의 복제 기능
MySQL 사용이 부적합한 경우
- SQL 준수가 필요한 경우
: MySQL은 표준 SQL을 완전히 준수하지 않음
- 동시성과 대용량 데이터 볼륨이 요구되는 경우
- MySQL은 일반적으로 읽기가 많은 작업에서 잘 수행되지만,
동시에 읽기와 쓰기 작업이 일어나는 경우는 문제가 될 수 있음
- 응용프로그램에 한 번에 많은 사용자가 데이터를 쓰는 경우,
PostgreSQL과 같은 다른 RDBMS가 더 나은 선택이 될 수 있음
주석
# 한줄 주석
-- 한줄 주석
/* 여러줄
주석*/
데이터 타입
1. 숫자 타입
- 정수 타입 (TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT)
- 고정 소수점 타입 (DECIMAL)
- 부동 소수점 타입 (FLOAT, DOUBLE)
- 비트값 타입 (BIT)
2. 문자열 타입
- CHAR (고정 문자열)
- VARCHAR (가변 길이 문자열)
- BINARY, VARBINARY
- BLOB, TEXT
- ENUM (미리 정의한 집합 안의 요소 중 하나만을 저장 가능)
- SET (미리 정의한 집합 안의 요소 중 여러 개를 동시에 저장할 수 있는 타입)
3. 날짜와 시간 타입
- DATE(날짜, 'YYYY-MM-DD')
- DATETIME (날짜 + 시간, 'YYYY-MM-DD HH:MM:SS')
- TIMESTAMP ('1997-01-01 00:00:01' UTC부터 시작하는 초수')
- TIME (시간, 'HH:MM:SS')
- YEAR (YEAR(4) : 4자리)
연산자
1. 산술 연산자
| + | - | * | / | DIV | % (or) MOD |
2. 대입 연산자
- = (SET 문이나 UPDATE 문의 SET 절에서만 대입연산자로 사용)
- := (비교 연산자로 해석되지 않는 대입 연산자)
3. 비교 연산자
| = | != | < , > , <=, >= |
- IS (왼쪽 피연산자와 오른쪽 피연산자가 같으면 참을 반환)
- IS NOT
- IS NULL (피연산자의 값이 NULL이면 참을 반환)
- IS NOT NULL
- BETWEEN a AND B (a~b 사이면 참을 반환, a와 b 포함)
- NOT BETWEEN a AND B
- IN() (피연산자의 값이 인수로 전달받은 리스트에 존재하면 참을 반환)
- NOT IN()
4. 논리 연산자
| AND (&&) |
OR ( || ) |
XOR | NOT (!) |
5. 비트 연산자
| AND 연산 | OR 연산 | XOR 연산 | NOT 연산 | left shift 연산 | right shift 연산 |
| & | | | ^ | ~ | << | >> |
* MySQL에서는 '0'과 '1'로만 이루어진 문자열 앞에 'b'를 붙여 2진수를 표현
제약 조건
: 데이터의 무결성을 지키기 위해, 데이터를 입력받을 때 실행되는 검사 규칙
- NOT NULL : NULL 값 저장 불가
- UNIQUE : 고유한 값을 가져야 함
- PRIMARY KEY : NOT NULL + UNIQUE
- FOREIGN KEY : 하나의 테이블을 다른 테이블에 의존하게 만듦
- DEFAULT : 필드의 기본값을 설정해야 함
* CREATE 문으로 테이블을 생성할 때나 ALTER 문으로 필드를 추가할 때 설정할 수 있음
* 아래와 같은 방식으로 사용
# create
CREATE TABLE Test(
ID INT NOT NULL,
Name VARCHAR(30),
ReserveDate DATE,
RoomNum INT
);
# alter
ALTER TABLE Reservation
MODIFY COLUMN Name VARCHAR(30) NOT NULL;
SQL 분류
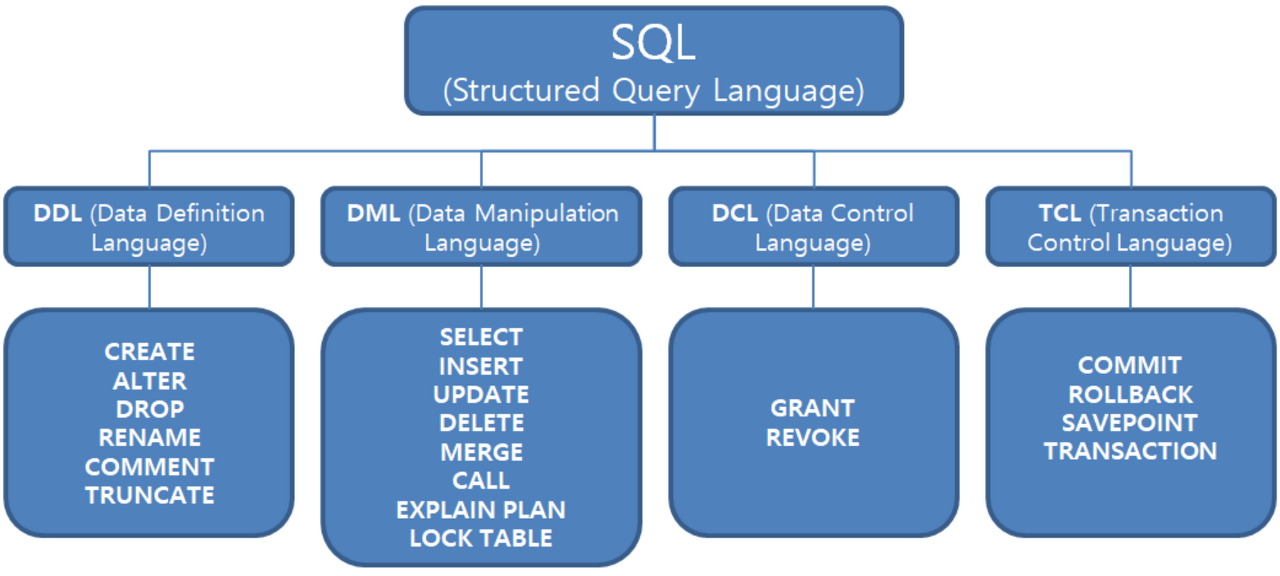
CREATE
- 새로운 데이터베이스 생성
- CREATE TABLE 테이블이름( 필드이름1 필드타입1, 필드이름2 필드타입2, ... )
CREATE TABLE Test
(
ID INT,
Name VARCHAR(30),
ReserveDate DATE,
RoomNum INT
);
ALTER
- 데이터베이스와 테이블 내용을 수정
- ALTER DATABASE
- ALTER TABLE
- ADD, DROP, MODIFY COLUMN
-- 새로운 필드 추가
ALTER TABLE Reservation
ADD Phone INT; # (ADD COLUMN 컬럼명 타입) - COLUMN 키워드 생략 가능
-- 필드 삭제
ALTER TABLE Reservation
DROP RoomNum;
-- 필드 타입 변경
ALTER TABLE Reservation
MODIFY COLUMN ReserveDate VARCHAR(20);
DROP
- 데이터베이스와 테이블 삭제
- DROP DATABASE 데이터베이스이름
- DROP TABLE 테이블이름
- TRUNCATE TABLE (테이블 자체가 아닌 테이블의 데이터만을 지우고 싶은 경우)
DROP DATABASE Hotel;
DROP TABLE Reservation;
TRUNCATE TABLE Reservation;
-- 데이터베이스나 테이블이 존재하지 않아서 발생하는 에러 방지
DROP DATABASE IF EXISTS Hotel;
DROP TABLE IF EXISTS Reservation;
INSERT
- 테이블에 새로운 레코드 추가
- INSERT INTO 테이블이름(필드이름1, 필드이름2, ...) VALUES (데이터값1, 데이터값2, ...)
- INSERT INTO 테이블이름 VALUES (데이터값1, 데이터값2, 데이터값3, ...)
* 2번째 경우에는 데이터베이스의 스키마와 같은 순서대로 필드의 값이 자동 대입
* 아래 필드 값은 생략 가능
1. NULL을 저장할 수 있도록 설정된 필드
2. DEFAULT 제약 조건이 설정된 필드
3. AUTO_INCREMENT 키워드가 설정된 필드
INSERT INTO Reservation(ID, Name, ReserveDate, RoomNum)
VALUES(5, '이순신', '2016-02-16', 1108);
-- 추가하는 레코드가 반드시 모든 필드의 값을 가져야 할 필요는 없음
-- 비어 있는 필드는 NULL 값을 가짐
INSERT INTO Reservation(ID, Name)
VALUES (6, '김유신');
UPDATE
- 테이블의 레코드 내용 수정
- 해당 테이블에서 WHERE 절의 조건을 만족하는 레코드의 값만 수정
- UPDATE 테이블이름 SET 필드이름1=데이터값1, 필드이름2=데이터값2, ... WHERE 필드이름=데이터값
UPDATE Reservation
SET RoomNum = 2002
WHERE Name = '홍길동';
-- WHERE 절 생략
-- 모든 레코드의 RoomNum 필드의 값이 2002로 변경됨
UPDATE Reservation
SET RoomNum = 2002;
DELETE
- 테이블의 레코드 삭제
- DELETE FROM 테이블이름 WHERE 필드이름=데이터값
DELETE FROM Reservation
WHERE Name = '홍길동';
-- WHERE절 생략
-- 테이블에 저장된 모든 데이터 삭제
DELETE FROM Reservation
SELECT
- 원하는 레코드를 가져옴
- SELECT 필드이름 FROM 테이블이름 [WHERE 조건]
-- 해당 테이블의 모든 필드 선택 (*)
SELECT *
FROM Reservation;
-- WHERE 절을 사용하여 검색할 레코드의 조건을 설정할 수 있음
SELECT *
FROM Reservation
WHERE Name = '홍길동';
-- AND , OR 을 통해 여러개의 조건을 같이 명시 가능
SELECT *
FROM Reservation
WHERE ID <= 3 AND ReserveDate > '2016-02-01';
-- 특정 필드만 선택
SELECT Name, RoomNum
FROM Reservation;
-- 조건을 만족하는 특정 필드만 선택
SELECT Name, ReserveDate
FROM Reservation
WHERE ID <= 3 AND ReserveDate > '2016-02-01';
-- 중복 값 제거 (DISTINCT)
SELECT DISTINCT Name
FROM Reservation;
-- 선택한 결과 정렬
-- default : ASC (오름차순)
SELECT *
FROM Reservation
ORDER BY ReserveDate DESC; -- 내림차순
-- 쉼표(,)를 사용하여 여러 필드의 데이터를 한 번에 정렬
SELECT *
FROM Reservation
ORDER BY ReserveDate DESC, RoomNum ASC;
-- 별칭(alias) 사용
-- 결과 예 )
-- ReserveDate | ReserveInfo
-- 2022-01-05 | 2014 : 홍길동
-- CONCAT() : 인수로 전달받은 문자열을 모두 결합하여 하나의 문자열로 반환하는 함수
SELECT ReserveDate, CONCAT(RoomNum, " : ", Name) AS ReserveInfo
FROM Reservation;
흐름 제어
1. CASE
- 값 비교
- 표현식의 논리 값에 따라 다른 값 반환
- CASE ... WHEN ... THEN ... END
select employee_id, first_name, salary,
case when salary > 15000 then '고액연봉'
when salary > 8000 then '평균연봉'
else '저액연봉'
end "연봉등급"
from employees;SELECT ANIMAL_ID, NAME,
CASE
WHEN (SEX_UPON_INTAKE LIKE 'Neutered%') OR (SEX_UPON_INTAKE LIKE 'Spayed%')THEN 'O'
ELSE 'X'
END AS '중성화'
FROM ANIMAL_INS
ORDER BY ANIMAL_ID;
2. IF()
- 조건에 따라 다른 값으로 조회하고 싶은 경우
- IF(조건문, TRUE, FALSE)
SELECT ANIMAL_ID, NAME,
IF((SEX_UPON_INTAKE LIKE 'Neutered%') OR (SEX_UPON_INTAKE LIKE 'Spayed%'), "O", "X") AS "중성화"
FROM ANIMAL_INS
ORDER BY ANIMAL_ID;
3. IFNULL()
- IFNULL(expr1, expr2)
- expr1이 NULL인 경우, expr2 반환
select employee_id 사번, first_name 이름, salary 급여, salary*12 연봉,
commission_pct, salary * (1 + ifnull(commission_pct, 0)) *12 "커미션포함 연봉"
from employees;
4. NULLIF()
- NULLIF(expr1, expr2)
- expr1과 expr2의 값이 서로 같으면 NULL 반환, 같지 않으면 expr1 반환
패턴 매칭
1. LIKE
- 원하는 패턴의 문자열 검색
- % : sub string (0개 이상)
- _ : 한 글자
* `like`를 `=`으로 사용하지 않도록 주의
-- 이름에 'x'가 들어간 사원의 사번, 이름
select employee_id, first_name
from employees
where first_name like '%x%';
-- where first_name = '%x%'; # '=' 불가!!!!
-- 이름의 끝에서 3번째 자리에 'x'가 들어간 사원의 사번, 이름
select employee_id, first_name
from employees
where first_name like '%x__';
2. REGEXP
- LIKE 보다, 더 복잡한 패턴을 검색하는 경우
| 패턴 | 설명 |
| . | 줄 바꿈 문자(\n)를 제외한 임의의 한 문자 |
| * | 해당 문자 패턴이 0번 이상 반복 |
| + | 해당 문자 패턴이 1번 이상 반복 |
| ^ | 문자열의 처음 |
| $ | 문자열의 끝 |
| | | 선택 (OR) |
| [...] | 괄호([]) 안에 있는 어떠한 문자 |
| [^...] | 괄호([]) 안에 있지 않은 어떠한 문자 |
| {n} | 반복되는 횟수 지정 |
| {m,n} | 반복되는 횟수의 최솟값과 최댓값 지정 |
-- 홍'으로 시작하거나, '산'으로 끝나는 이름
SELECT * FROM Reservation
WHERE Name REGEXP '^홍|산$';
타입 변환
1. BINARY
- 연산자 뒤에 오는 문자열을 바이너리 문자열로 변환
SELECT BINARY 'a' = 'A'; -- false
SELECT 'a' = 'A'; -- true
2. CAST()
- 인수로 전달받은 값을 명시된 타입으로 변환
- 변환하고자 하는 타입을 AS 절을 이용하여 명시
- CAST(expr AS type)
select cast(1 as char) as "cast 문자",
cast('23' as signed) as "cast 숫자",
cast('20230822' as date) as "cast 날짜";
3. CONVERT()
- CAST() 함수처럼 인수로 전달받은 값을 명시된 타입으로 변환하여 반환
- CONVERT(expr, type)
SELECT CONVERT(20230822, DATE);
다중 테이블 연산
1. JOIN
: 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현해 줌
1) INNER JOIN
- 단순히 from 절에 `,`를 사용하는 경우, inner join 으로 연산
- ON 절과 함께 사용되며, ON 절의 조건을 만족하는 데이터만 가져옴
- 표준 SQL과는 달리 MySQL에서는 JOIN, INNER JOIN, CROSS JOIN이 모두 같은 의미로 사용됨
- 테이블1 INNER JOIN(JOIN) 테이블2 ON 조건
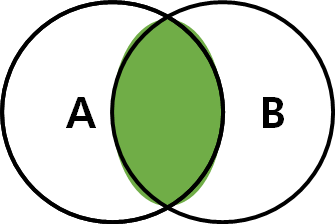
SELECT * FROM TableA A JOIN TableB B ON A.key = B.key;
2) LEFT JOIN
- 첫 번째 테이블을 기준으로, 두 번째 테이블을 조합하는 JOIN
- ON 절의 조건을 만족하지 않는 경우에는 첫 번째 테이블의 필드 값은 그대로 가져옴
but, 해당 레코드의 두 번째 테이블의 필드 값은 모두 NULL로 표시
- 테이블1 LEFT JOIN 테이블2 ON 조건
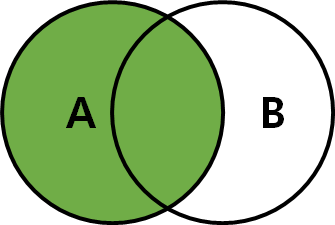
-- LEFT OUTER JOIN
SELECT * FROM TableA A LEFT JOIN TableB B ON A.key = B.key;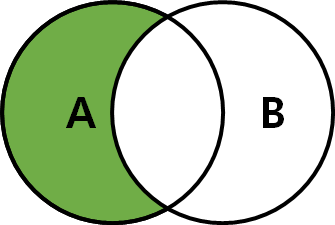
-- 순수 A만 구할 때
SELECT * FROM TableA A LEFT JOIN TableB B ON A.key = B.key
WHERE B.Key IS NULL;
3) RIGHT JOIN
- 두 번째 테이블을 기준으로, 첫 번째 테이블을 조합하는 JOIN
- ON 절의 조건을 만족하지 않는 경우에는 두 번째 테이블의 필드 값은 그대로 가져옴
but, 해당 레코드의 첫 번째 테이블의 필드 값은 모두 NULL로 표시
- 테이블1 RIGHT JOIN 테이블2 ON 조건
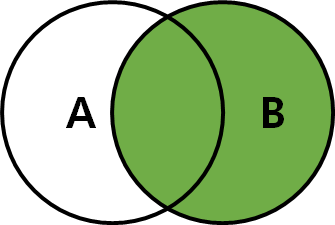
-- RIGHT OUTER JOIN
SELECT * FROM TableA A RIGHT JOIN TableB B ON A.key = B.key;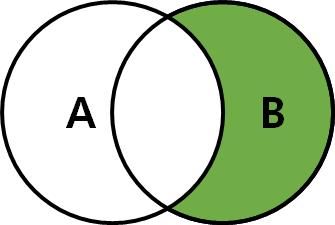
-- 순수 B만 구할 때
SELECT * FROM TableA A RIGHT JOIN TableB B ON A.key = B.key
WHERE A.Key IS NULL;
4) FULL OUTER JOIN
- MySQL은 FULL OUTER JOIN이 없지만, LEFT JOIN 과 RIGHT JOIN을 이용해 FULL OUTER JOIN 사용 가능
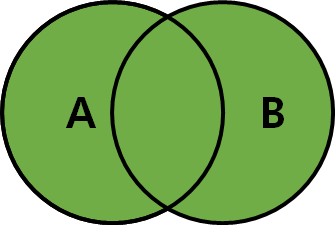
SELECT * FROM TableA A LEFT JOIN TableB B
UNION
SELECT * FROM TableA A RIGHT JOIN TableB B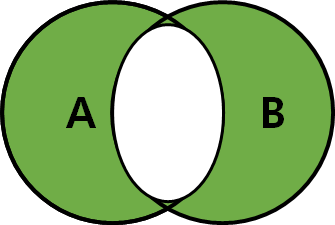
-- 교집합 제외
SELECT * FROM TableA A LEFT JOIN TableB B
UNION
SELECT * FROM TableA A RIGHT JOIN TableB B
WHERE A.key IS NULL OR B.key IS NULL
2. UNION
- 여러 개의 SELECT 문의 결과를 하나의 테이블이나 결과 집합으로 표현할 때 사용
- SELECT 필드이름 FROM 테이블이름 UNION SELECT 필드이름 FROM 테이블이름
- DISTINCT 키워드를 따로 명시하지 않아도 기본적으로 중복되는 레코드를 제거
- 중복되는 레코드까지 모두 출력하고 싶다면, `ALL` 키워드를 사용
SELECT 필드이름 FROM 테이블이름 UNION ALL SELECT 필드이름 FROM 테이블이름
SELECT Name
FROM Reservation
UNION -- UNION ALL
SELECT Name
FROM Customer;
3. 서브 쿼리
- 다른 쿼리 내부에 포함되어 있는 SELETE 문
- 서브쿼리를 포함하고 있는 쿼리 = 외부쿼리(outer query) / 서브쿼리 = 내부쿼리(inner query)
- 서브쿼리는 반드시 괄호(())로 감싸져 있어야 함
'CS > 데이터베이스' 카테고리의 다른 글
| 식별관계 비식별관계 (0) | 2023.04.17 |
|---|---|
| Index, View, Transaction (인덱스, 뷰, 트랜잭션) (0) | 2023.04.12 |
| Key (후보키, 기본키, 슈퍼키, 대체키, 외래키) (0) | 2023.04.12 |
| 데이터베이스 정규화(Normalization) (0) | 2023.03.30 |
| DBMS (데이터베이스 관리 시스템) (0) | 2023.01.12 |
