Index (인덱스)
- 테이블에서 데이터 조회 시 동작속도를 높여주는 자료구조
- (컬럼의 값, 레코드 저장 주소) 를 key와 value의 쌍으로 저장
- MYI (MySQL Index) 파일에 저장

Index 장점과 단점
장점
- 테이블 조회 시 속도와 성능이 향상
- 시스템의 전반적인 부하 감소 가능
💡 Index를 사용하면 좋은 경우
1. 규모가 큰 테이블
2. 삽입, 삭제, 수정 작업이 적은 경우
3. 데이터 중복도가 낮은 경우
4. WHERE, ORDER BY, JOIN 등이 자주 사용되는 경우
💡 데이터 중복이 많은 경우, INDEX 사용이 비효율적인 이유
ex) 이름, 나이, 성별 세 가지 컬럼을 갖고 있는 테이블
이름 - 다양한 경우의 수
나이 - INT 타입
성별 - 남, 녀 (2가지)
이 경우, 이름에 대해서만 인덱스를 생성하는 것이 효율적
왜 성별이나 나이는 인덱스를 생성하면 비효율적일까?
: 값의 range 가 적은 성별은 인덱스를 읽고, 다시 한 번 디스크 I/O 가 발생하기 때문!!
단점
- 인덱스 관리를 위한 추가 작업 및 저장 공간(DB의 약10%) 필요
- 잘못 사용하는 경우 오히려 검색 성능 저하
- 처음 인덱스 생성 시 많은 시간 소요
- 데이터의 변경(UPDATE, INSERT, DELETE)이 자주 일어나는 경우 성능 저하
💡 데이터의 변경이 자주 일어나는 경우, 성능이 저하되는 이유
INSERT - INDEX에 대한 데이터도 추가해야 하므로 그만큼 성능에 손실 발생
DELETE - INDEX 에 존재하는 값은 삭제하지 않고 사용 안한다는 표시로 남김
(즉, row 수는 그대로!!)
UPDATE - INSERT와 DELETE의 문제점을 동시에 수반
(이전 데이터가 삭제되고 그 자리에 새 데이터가 들어오는 개념이기 때문)
Index 종류
클러스터형 인덱스 (Clustered index)
- 테이블 당 하나만 생성 가능
- 특정 나열된 데이터들을 일정 기준으로 정렬해주는 인덱스
- 보조 인덱스보다 검색 속도가 더 빠름 (단 삽입/수정/삭제는 더 느림)
- 클러스터형 인덱스 생성 시 데이터 페이지 전체가 다시 정렬
- 따라서, 이미 대용량의 데이터가 입력된 상태라면, 심각한 부하 발생
- 어느 열에 클러스터형 인덱스를 생성하는지에 따라 시스템의 성능이 달라짐
💡 MySQL의 경우
Primary Key가 있다면 Primary Key를 클러스터형 인덱스로,
없다면 unique하면서 Not null인 컬럼을,
그것도 없으면 임의로 보이지 않는 컬럼을 만들어 클러스터형 인덱스로 지정
보조 인덱스 (Secondary index)
- 테이블 당 여러 개 생성 가능 (단, 너무 많이 생성하면 오히려 성능 저하)
- 개념적으로 후보키에만 부여 가능한 INDEX
- 보조 인덱스 생성 시 데이터 페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스 구성 (자동 정렬되지 않음)
- 클러스터형 인덱스보다 검색속도는 느리지만 데이터의 입력/수정/삭제 시 성능 부하가 적음
💡 후보키
: 기본키로 사용할 수 있는 속성들 (튜플을 유일하게 식별하며, 유일성과 최소성을 만족)
Index 자료 구조
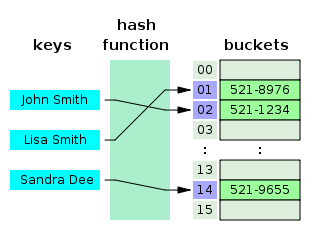
Hash Table
- 빠른 데이터 검색이 필요한 경우 유용
- 시간 복잡도 : O(1)
- INDEX에서 해시 테이블이 사용되는 경우는 제한적
- 해시함수는 값이 하나라도 달라지면 완전히 다른 해시 값을 생성
- 부등호 연산이 자주 사용되는 데이터베이스 검색을 위해서는 적합하지 않음
B-Tree
- 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree의 일종
- 자식들의 Balance를 잘 유지하면, 최악의 경우에도 O(log N)의 시간이 보장됨
- 어느 한 데이터의 검색은 효율적이지만,
- 모든 데이터를 한번 순회하기 위해 트리의 모든 노드를 방문해야하므로 비효율적임

B+Tree
- B-Tree의 단점을 개선시킨 자료구조
- (최선의 경우, 리프 노드까지 가지 않아도 되는 B-Tree 에 비해 무조건 리프 노드까지 탐색해야 한다는 단점도 존재)
- leaf node에만 데이터를 저장하고, leaf node가 아닌 node에는 자식 포인터만 저장
- leaf node 끼리는 Linked list로 연결 (데이터베이스 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생)
- InnoDB에서
- 같은 레벨의 노드들끼리는 Double Linked List
- 자식 노드들은 Single Linked List로 연결되어 있음


Index 생성전략
- 인덱스는 열 단위에 생성
- where 절에서 사용되는 열에 생성
- where 절에 사용되는 열이라도 자주 사용해야 가치가 있음
- 데이터 중복도가 높은 열에는 인덱스를 만들어도 효과가 없음 (중복도가 낮은 열에 생성)
- 외래키를 설정한 열에는 자동으로 외래키 인덱스가 생성됨
- 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋음
- 데이터 변경(삽입, 수정, 삭제) 작업이 얼마나 자주 일어나는지 고려해야함
- 클러스터형 인덱스는 테이블당 하나만 생성할 수 있음
- 사용하지 않는 인덱스는 제거
SQL 문 in Indx
-- 클러스터형 인덱스 생성
ALTER TABLE clusterTBL
ADD CONSTRAINT PK_clusterTBL_userID
PRIMARY KEY (userID);
-- 테이블에 생성된 인덱스 확인
SHOW INDEX FROM userTBL;
-- 보조 인덱스 생성
CREATE UNIQUE INDEX index_name
ON table_name (index_column);
-- 두 컬럼을 조합해 인덱스 생성
CREATE INDEX idx_userTBL_userName_birthYear
ON userTBL (name, birthYear);
-- 이전보다 빠른 검색
SELECT * FROM userTBL WHERE name= "짱구" and birthYear = '2007';
-- 인덱스 삭제
DROP INDEX index_name ON table_name;
View (뷰)
- 데이터베이스에 존재하는 가상의 테이블
- 실제 행과 열을 가지고 있지만, 데이터를 저장하고 있지는 않음 (SQL만 저장)
- 다른 테이블에 있는 데이터를 보여주는 것일 뿐, 데이터 자체를 포함하고 있는 것이 아님

View의 장점과 단점
장점
- 논리적 데이터 독립성 제공
- 사용자의 데이터 관리를 간단하게 해줌 (데이터 조작 연산의 간소화)
- 동일 데이터에 대해 동시에 여러 사용자의 상이한 응용이나 요구를 지원
- 접근 제어를 통한 자동 보안 제공 (테이블 전체가 아닌 필요한 속성만 보여줌)
💡 논리적 데이터 독립성
: 뷰를 이용하면 다른 응용 프로그램이나 데이터베이스에 영향을 주지 않고,
응용 프로그램이 원하는 형태로 데이터에 접근할 수 있기 때문에
논리적 데이터 독립성을 구현할 수 있음
단점
- 독립적인 인덱스를 가질 수 없음
- ALTER VIEW문을 사용할 수 없음 ( VIEW 정의 변경 불가 )
- 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신 연산에 제약이 따름
View 종류
Simple View (단순 뷰)
- 하나의 테이블로 생성된 뷰
- 그룹 함수, distnict 사용 불가능
- DML 사용 가능
💡 DML (Data Manipulation Language) : INSERT, SELECT, UPDATE, DELETE
Complex View (복합 뷰)
- 여러 개의 테이블로 생성된 뷰 (JOIN)
- 그룹 함수, distnict 사용 가능
- DML 사용 불가능
Inline View (인라인 뷰)
- FROM 절 내 SQL 문장
- 일반적으로 가장 많이 사용
SQL문 in View
-- 생성
-- create view 뷰이름 as select 필드이름1, 필드이름2, ... from 테이블이름 where 조건;
CREATE VIEW seoul_custormer(name, phone)
AS SELECT name, phone
FROM custormer
WHERE addr = 'seoul';
-- 삭제
-- DROP VIEW 뷰이름 RESTRICT or CASCADE
-- RESTRICT : 다른곳에서 뷰를 참조하고 있으면 삭제 취소
-- CASCADE : 뷰를 참조하는 다른 뷰나 제약 조건까지 모두 삭제
DROP VIEW seoul_custormer RESTRICT;
-- 조회
SELECT * FROM seoul_custormer
-- 대체 (설정한 필드를 대체하기 위해서는 새로운 View로 대체)
create or replace view 뷰이름
as
select 필드이름1, 필드이름2, ...
from 테이블이름
where 조건;
-- 수정
alter view 뷰이름
as
select 필드이름1, 필드이름2, ...
from 테이블이름;
Transaction (트랜잭션)
: 데이터베이스에서의 논리적 작업 단위 (작업의 완전성 보장)
💡 Transaction과 Lock
잠금(Lock)과 트랜잭션은 서로 비슷한 개념 같지만
잠금 - 동시성을 제어하기 위한 기능
트랜잭션 - 데이터의 정합성을 보장하기 위한 기능
잠금 : 여러 커넥션에서 동시에 동일한 자원을 요청할 경우 순서대로 한 시점에는 하나의 커넥션만 변경할 수 있게 해주는 역할
* 여기서 자원은 레코드나 테이블을 말함
* 트랜잭션은 꼭 여러 개의 변경 작업을 수행하는 쿼리가 조합되었을 때만 의미있는 개념은 아님
트랜잭션
: 하나의 논리적인 작업 셋 중 하나의 쿼리가 있든 두 개 이상의 쿼리가 있든 관계없이
논리적인 작업 셋 자체가 100% 적용되거나 아무것도 적용되지 않아야 함을 보장
ex) HW /SW 에러 같은 문제로 작업이 실패하는 경우
Transaction의 특성 (ACID)
원자성 (Atomicity)
- 트랜잭션 관련 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장
- All or Nothing (트랜잭션이 DB에 모두 반영되거나, 반영되지 않거나)
일관성 (Consistency)
- 트랜잭션이 성공적으로 실행 완료되는 경우, 언제나 일관성 있는 데이터베이스 상태로 유지하는 것
- 트랜잭션이 완료된 다음의 상태에서도 트랜잭션이 일어나기 전의 상황과 동일하게 데이터의 일관성을 보장
- ex) 은행 송금 기능 - 송금자와 수금자의 잔액 합이 달라지거나, 잔액을 나타내는 자료형이 바뀌는 등의 모순이 발생해선 안됨
독립성 (Isolation)
- 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것 (각각의 트랜잭션은 독립적으로 수행)
- 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미
지속성 (Durability)
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함
- 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있음
- 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있음
Transaction 연산
1. Commit
: 트랜잭션이 성공적으로 종료된 후, 데이터베이스가 일관된 상태를 유지할 때
갱신 연산이 완료되었다고 트랜잭션 관리자에게 알려주고 결과를 최종적으로 데이터베이스에 반영하는 연산
2. Rollback
: 트랜잭션이 지금까지 실행한 연산의 결과가 취소되고 트랜잭션 수행 이전의 상태로 돌아가는 연산

Transaction 상태

활성화 (Active) : 트랜잭션이 실행중이며 동작중인 상태
실패 (Failed) : 트랜잭션이 더이상 정상적으로 진행 할 수 없는 상태
부분완료 (Partially Committed) : 트랜잭션의 commit이전 sql문이 수행되고 commit만 남은 상태
완료 (Committed) : 트랜잭션이 정상적으로 완료된 상태
철회(Aborted) : 트랜잭션이 취소되고 트랜잭션 실행 이전 데이터로 돌아간 상태
💡 Transaction 사용시 주의점
Transaction은 최소 코드에 적용하는 것이 좋음 = Transaction의 범위 최소화
일반적으로 데이터베이스 커넥션은 개수가 제한적이기 때문에
각 단위 프로그램이 커넥션을 소유하는 시간이 길어지면 사용 가능한 여유 커넥션의 개수는 줄어듦
(그러다보면 어느 순간에는 각 단위 프로그램에서 커넥션을 기다려야 하는 상황이 발생할 수도 있음)
Transaction 격리 수준
: 복수개의 트랜잭션이 한번에 처리될 때,
특정 트랜잭션이 변경하거나 조회하고 있는 데이터에 대해서
다른 트랜잭션에 대해 조회 허용 여부를 결정하는 것
💡 데이터 정합성과 성능은 반비례
(밑으로 갈수록 격리 수준이 낮아지며, 동시 처리 성능이 높아짐)
SERIALIZABLE (직렬화 가능)
- 특정 트랜잭션이 사용중인 테이블의 모든 행을 다른 트랜잭션이 접근하지 못하도록 함
- 가장 높은 데이터 정합성을 갖지만, 성능은 가장 떨어짐
- 단순한 SELECT 쿼리 실행시에도 데이터베이스 락이 걸려 다른 트랜잭션이 DB에 접근 불가
REPEATABLE READ (반복 가능한 읽기)
- 특정 행을 조회시 항상 같은 데이터를 응답하는 것을 보장하는 격리 수준
- 하지만, SERIALIZABLE과 다르게 행이 추가되는 것을 막지는 않음
- Phantom Read 발생 가능

READ COMMITTED (커밋된 읽기)
- 커밋이 완료된 트랜잭션의 변경사항만 다른 트랜잭션에서 조회할 수 있도록 허용하는 격리 수준
- Phantom Read, Non-Repeatable Read 발생 가능

READ UNCOMITTED (커밋되지 않은 읽기)
- 커밋이 되지 않은 트랜잭션의 데이터 변경 내용을 다른 트랜잭션이 조회하는 것을 허용하는 격리 수준
- Dirty Read, Non-Repeatable Read, Phantom Read 발생 가능

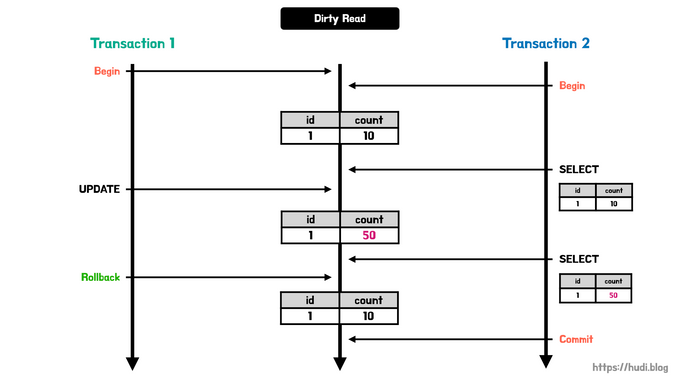
💡 Transaction 격리 수준에 따라 발생 가능한 문제점
- Dirty Read ( 더티 리드 )
: 데이터가 변경되었지만, 아직 커밋되지 않은 상황에서
다른 트랜잭션이 해당 변경 사항을 조회할 수 있는 문제
- Non-Repeatable Read ( 반복 불가능한 조회 )
: 같은 트랜잭션 내에서 같은 데이터를 여러번 조회했을 때
읽어오는 데이터가 달라지는 문제
- Phantom Read ( 팬텀 리드 )
: 조회한 결과의 행이 새로 생기거나 없어지는 문제
(Non-Repeatable Read의 한 종류)
'CS > 데이터베이스' 카테고리의 다른 글
| 식별관계 비식별관계 (0) | 2023.04.17 |
|---|---|
| Key (후보키, 기본키, 슈퍼키, 대체키, 외래키) (0) | 2023.04.12 |
| 데이터베이스 정규화(Normalization) (0) | 2023.03.30 |
| MySQL 정리 (0) | 2023.02.13 |
| DBMS (데이터베이스 관리 시스템) (0) | 2023.01.12 |
