기존 seq2seq 모델의 한계
입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스 정보가 일부 손실
*이를 보완하기 위해 Attention 이용했었음
Transformer
기존의 RNN 기반의 모델과 달리, Self-Attention을 사용하여 입력 시퀀스의 전체적인 의미를 파악하고 처리하는 방식으로 동작
* RNN을 모두 Attention으로 대체

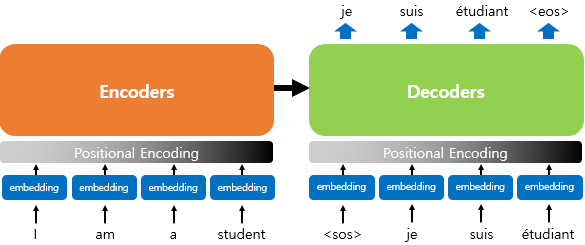
Encoder
Input Embedding
입력 문장의 각 단어를 고정 길이의 벡터로 변환
Positional Encoding
- RNN이은 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하기 떄문에 단어의 위치 정보를 가질 수 있었음
- 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있음
- 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용
- 인코더와 디코더에서 공통적으로 가지고 있는 서브층

위치 정보를 더할 때, 사인 함수와 코사인 함수를 이용
* 임베딩 벡터가 모여 만들어진 문장 벡터 행렬과 포지셔널 인코딩 행렬의 덧셈 연산을 통해 이루어짐

Multi-head Self-Attention ( Encoder Self-Attention )
ex) '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.'
- 그것(it)이 동물(animal)과 연관되었을 확률이 높다는 것을 찾아내는 역할
- 즉, 입력 문장 내의 단어들끼리 유사도를 구하고, 단어의 의미를 파악!!
- 병렬 attention 사용 (WQ , WK , WV 의 값은 어텐션 헤드마다 전부 다름)
- 병렬 attention 수행 후 모든 attention 헤드를 연결



Query = Key = Value
: 입력 문장의 모든 단어 벡터들
셀프 어텐션에서 각 단어의 정보를 얻기 위해 사용되는 Query, Key, Value
Query: 어텐션을 수행할 단어의 정보를 담은 벡터
Key: 다른 단어들과의 유사도를 계산할 때 사용되는 벡터
Value: 유사도가 계산된 단어의 정보를 담은 벡터
Add & Norm
- 잔차 연결 + 층 정규화
- 인코더와 디코더에서 공통적으로 가지고 있는 서브층
- Residual Connection : 서브층의 입력과 출력을 더하는 것
- Layer Normalization : 텐서의 마지막 차원에 대해서 평균과 분산을 구한 후 특정 수식을 통해 값을 정규화하여 학습을 도움

Feedforward Neural Network
- 완전 연결 FFNN(Fully-connected FFNN)
- 인코더와 디코더에서 공통적으로 가지고 있는 서브층
- 어텐션으로부터 얻은 정보를 활용하여, 입력으로부터 얻은 정보를 변환하고(더 잘 처리할 수 있는 형태로), 다음 레이어로 전달


정리
Attention을 통해 입력 문장의 정보를 추출하고, 이를 FFNN을 사용하여 변환하여 출력함으로써
입력 문장의 의미를 보다 효과적으로 추출하고, 모델의 성능을 향상시킬 수 있음
Decoder
Output Embedding
출력 문장의 각 단어를 고정 길이의 벡터로 변환
Masked Multi-head Self-Attention ( Masked Decoder Self-Attention )
- 현재 위치에서 출력할 단어의 의미를 파악
- 트랜스포머는 문장 행렬로 입력을 한 번에 받음
- 현재 시점의 단어를 예측할 때, 입력 문장 행렬로부터 미래 시점의 단어까지도 참고하는 현상이 발생할 수 있음
- mask값에다가 -1e9라는 아주 작은 음수값을 곱한 후 어텐션 스코어 행렬에 더해줌 = look-ahead mask
- 자기 자신보다 미래에 있는 단어들은 참고하지 못하도록!!

Query = Key = Value
look-ahead mask를 한다고해서 padding mask가 불필요한 것이 아니므로 look-ahead masks는 padding mask를 포함하도록 구현
Multi-head Attention ( Encoder - Decoder Attention )
- 디코더가 다음 단어를 생성할 때마다, 현재 생성 중인 단어와 관련된 정보를 인코더에서 가져와 이를 기반으로 다음 단어를 예측
- 디코더가 인코더의 단어를 참조하여 단어 간 상호 관계를 파악하면, 번역/요약/질문/응답 등의 작업에서 더 정확한 결과를 얻을 수 있음

Query: 디코더 벡터 ↔ Key = Value: 인코더 벡터
Query : 디코더의 이전 시점에서 예측한 단어의 정보를 담은 벡터
Key와 Value : 인코더에서의 셀프 어텐션에서 사용한 Key와 Value 벡터
* 디코더가 번역 작업을 수행할 때, 이전 시점에서 출력한 단어를 다음 단어를 예측하기 위해 입력으로 사용
Cost Function
- 주로 cross-entropy 손실 함수를 사용
- 디코더에서 각 단어별로 예측된 확률 분포와 정답 레이블을 이용하여 손실 함수를 계산
'AI' 카테고리의 다른 글
| BERT (Bidirectional Encoder Representations from Transformers) (0) | 2023.05.09 |
|---|---|
| Optimizer (0) | 2023.05.09 |
| Gradient Descent (0) | 2023.05.08 |
| Dropout (0) | 2023.05.02 |
| Pre-training, Transfer Learning, Fine-tuning (0) | 2023.04.30 |
